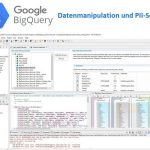
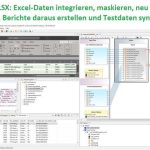
❌ UniKix TPE und BPE ❌ Transaktionsverarbeitung und Batch-Sortierung von VSAM- und sequentiellen Daten ❗
Mainframe CICS Sort Rehosting: JCL Sorts in UniKix BPE und TPE migrieren! Herausforderungen: Wenn Sie vom Mainframe zu "offenen Systemen" wechseln, arbeiten Sie möglicherweise mit dem Mainframe Rehosting Solutions Team von NTT DATA (früher Dell, Clerity, Sun, Blue Phoenix Mehr